
Проблема качественного контента для целей продвижения сайта
В современном SEO одним из ключевых факторов успеха является качественный уникальный контент. Однако зачастую у владельцев сайтов возникают проблемы с созданием такого контента – они либо не могут предоставить его в нужном объеме и качестве, либо вообще не предоставляют.
Традиционно для решения этой проблемы привлекаются сторонние специалисты-копирайтеры или контент-агентства. Однако у них, как правило, нет глубоких знаний о бизнесе и тематике сайта. Поэтому качество создаваемого ими контента оставляет желать лучшего.
В последнее время появляется новое решение – использование технологий искусственного интеллекта и машинного обучения для автоматической генерации контента. Эти технологии известны уже десятилетиями, но лишь в последние годы достигли уровня, позволяющего создавать разнообразные качественные тексты.
ИИ способен анализировать большие объемы информации и на их основе формировать уникальные статьи. При достаточном количестве исходных данных по тематике сайта, он может создавать релевантный целевой контент. Это позволяет частично решить проблему нехватки качественного уникального контента для SEO. Таким образом, именно технологии искусственного интеллекта открывают перед нами новые возможности в продвижении сайтов. Их применение для автоматической генерации контента является одним из перспективных направлений развития современного SEO.
Появление и развитие технологий генерации текста на основе ИИ
Развитие технологий искусственного интеллекта в последние годы привело к появлению так называемых генеративных нейросетевых моделей, способных к анализу, обработке и генерации текстов. В отличие от предыдущих подходов в области обработки естественного языка, эти модели могут не просто анализировать текст, но и самостоятельно его создавать.
Первыми технологии анализа текста на основе ИИ стали применять поисковые системы – для борьбы со спамом, классификации страниц, улучшения релевантности результатов поиска. Уже много лет выдача в Яндексе, Google и других поисковиках формируется с использованием нейросетей.
Однако сама генерация новых текстов ранее не использовалась. Результаты поиска состоят из сниппетов с реальных страниц, которые лишь незначительно могут редактироваться и комбинироваться. Ситуация изменилась с недавним прогрессом в области генеративного ИИ.
Основные принципы обучения нейронных сетей
Чтобы понять, как работает генерация текста в современных нейросетевых моделях, нужно разобраться в принципах их работы. В основе лежат технологии глубокого обучения искусственных нейронных сетей. Обычная нейросеть состоит из входного, выходного и нескольких скрытых слоев нейронов.
Обучение такой сети происходит на размеченных данных – когда вместе с входными данными (скажем, текстом письма) задано правильное выходное значение (является ли это письмо спамом). Сеть обрабатывает входные данные и выдает свой результат, который сравнивается с правильным ответом. Если результат не совпадает, веса нейронов корректируются так, чтобы в следующий раз ответ был более точным.
Так постепенно, на больших объемах размеченных данных, сеть обучается решать нужную задачу. Главное преимущество – обучение происходит без явного задания правил, сеть сама извлекает закономерности из данных.
Трансформеры и большие языковые модели (LLM)
Прорывом в развитии ИИ стало создание архитектуры трансформеров. Трансформеры показывают качественно более высокие результаты во многих задачах обработки данных, особенно текстов. Именно трансформеры лежат в основе современных нейросетей для генерации текстов.
Следующим этапом развития стало создание больших языковых моделей (large language models – LLM) на архитектуре трансформеров. Идея здесь в том, чтобы обучить нейросеть на как можно более обширном наборе разнообразных текстов.
Такая модель, проанализировав огромные объемы данных, может извлекать скрытые закономерности и понимать смысл текста. После обучения ее можно использовать для выполнения различных задач – классификации, суммаризации, генерации новых текстов и др.
Генерация нового текста происходит при помощи специальной входной последовательности символов – промпта. В промпте задается тема, направление, объем будущего текста. Модель анализирует промпт и генерирует подходящий результат.
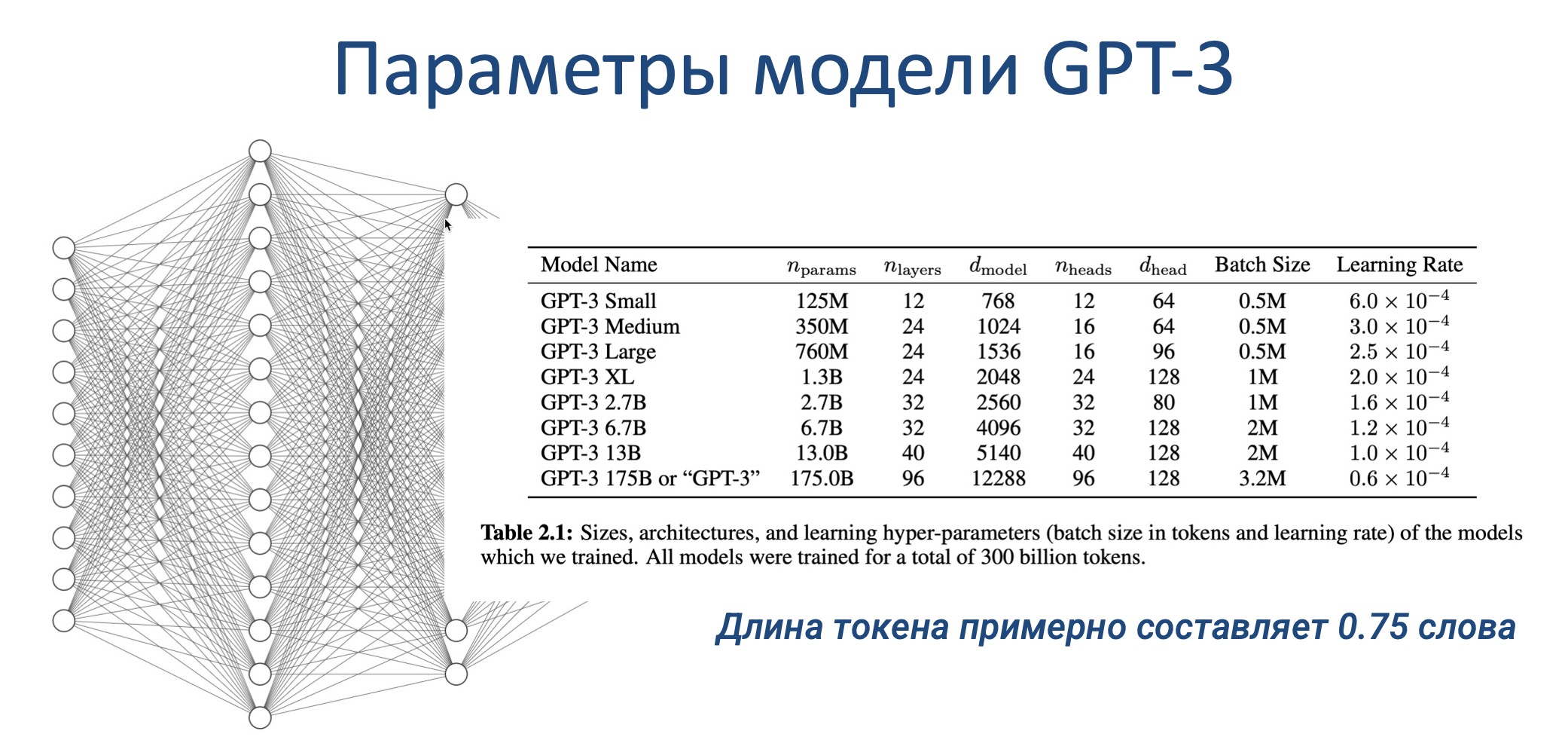
Чем крупнее модель (больше данных для обучения, сложнее архитектура, больше нейронов), тем выше качество генерируемых текстов. Например, модель GPT-3, имеющая 175 миллиардов параметров, может создавать весьма разумные, связные и грамотные тексты на основе заданных в промпте условий.
Как обучалась модель GPT-3
Одной из наиболее известных моделей для генерации текста является GPT-3, представленная в 2020 году. Ее предшественники, GPT-1 и GPT-2, разработчики даже не публиковали, поскольку качество текстов было невысоким. Но в GPT-3 удалось достичь гораздо лучших результатов.
Это стало возможным благодаря использованию огромной по размерам нейросети, содержащей 175 миллиардов параметров и 96 слоев. На ее обучение было затрачено 300 миллиардов текстовых единиц (токенов) и почти 5 миллионов долларов только на вычислительные мощности.
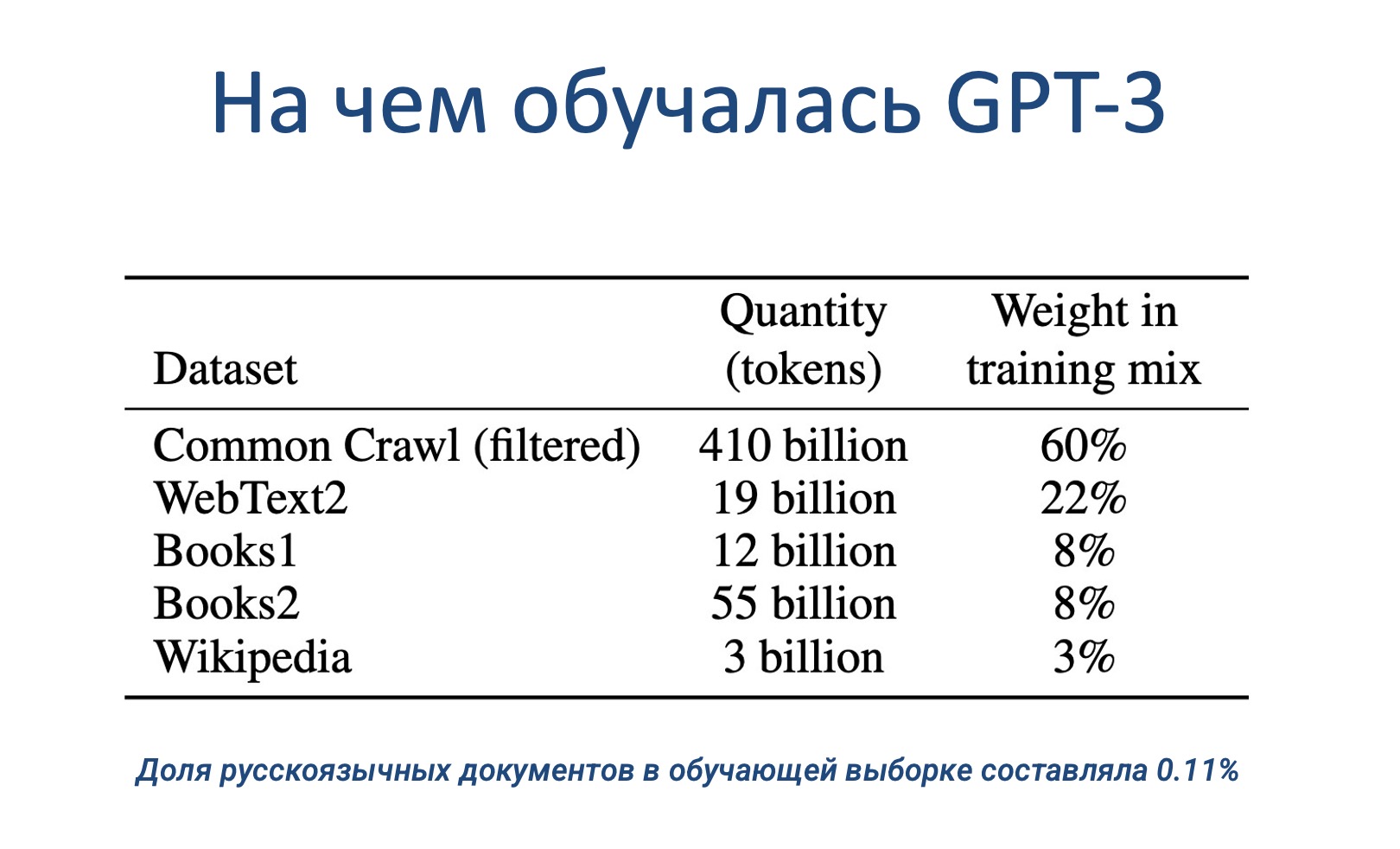
Подавляющая часть данных для обучения была взята из открытых источников в интернете – 410 миллиардов токенов из разнообразных документов и веб-страниц. Еще примерно 80 миллиардов составили тексты книг. Доля Википедии оказалась небольшой – всего 3%.
Хотя модель обучалась и на русскоязычных данных, их доля была лишь 0,11%. Это говорит о том, что качество генерации на русском языке может быть не так высоко, как для английского. Тем не менее, GPT-3 уже продемонстрировала впечатляющие результаты в автоматическом создании осмысленных и грамотных текстов на заданные темы на разных языках.
GPT-3 и GPT-4 от компании OpenAI
Разработчиком модели GPT-3 является компания OpenAI. При оценке качества работы подобных языковых моделей используется множество различных метрик в зависимости от решаемых задач. Однако четко прослеживается общая закономерность: чем больше параметров (нейронов и связей) в модели и чем больше данных использовалось для обучения, тем выше качество генерируемых текстов.
Это подтверждает, в частности, модель GPT-4, представленная в 2022 году. По сравнению с GPT-3 количество ее параметров возросло с 175 млрд до уже 176 триллионов! Соответственно, качество генерируемых ею текстов гораздо выше. Это классический принцип в нейросетевом ИИ: увеличение размера модели (количества нейронов и связей) и объема данных для обучения приводит к росту качества результатов.
Конечно, создание таких гигантских моделей требует колоссальных вычислительных мощностей и финансовых затрат. Но отдача тоже впечатляющая: современные ИИ модели могут генерировать весьма разумные и осмысленные тексты на заданные темы, что открывает широкие горизонты для их применения, в том числе в SEO.
Другие LLM – Claude, Mistral, LLaMa и вклад Google
Пионером в создании больших языковых моделей стал Google. По словам Илона Маска, еще в 2015 году на встрече с одним из основателей Google Ларри Пейджем он узнал о разработках Google в этой сфере. Осознав масштаб грядущих технологий, Маск решил создать альтернативный проект OpenAI, чтобы не допустить монополии Google на этом поле.
Впоследствии от OpenAI откололась группа разработчиков, создавшая компанию Anthropic и модель Claude. Еще одна модель, Mistral, была разработана выходцами из Meta (Facebook). Таким образом, сейчас лидируют три компании: Google, OpenAI и Meta, хотя число языковых моделей растет с каждым днем.
| Модель | Разработчик | Параметров | Лицензия |
|---|---|---|---|
| Mistral | Mistral AI | 46.7B | apache-2.0 |
| GPT-4 | OpenAI | 1.76T | |
| GPT-3 | OpenAI | 175B | |
| Claude 2 | Anthropic | неизвестно | |
| LLaMA 2 | Meta | 70B | Custom LLaMa 2 |
| BART | 406M | apache-2.0 | |
| BERT | 336M | apache-2.0 |
Важное отличие в том, что модели от Google, Meta и Mistral распространяются под открытыми лицензиями и доступны для свободного использования. А вот доступ к коммерческим моделям от OpenAI и Anthropic сильно ограничен, права на них контролируют крупные технологические компании вроде Microsoft и Amazon.
Хотя открытые модели тоже впечатляют размерами, их обучение и применение требует немалых вычислительных мощностей.
Примеры работы моделей по генерации текста
Современные языковые ИИ-модели способны не только анализировать огромные массивы текстов, но и самостоятельно генерировать новые. Это открывает возможность автоматического создания контента для сайтов.
Например, если задать модели вопрос “Что такое SEO?”, она даст развернутый, грамотный и исчерпывающий ответ, основанный на анализе всех доступных ей текстовых данных по этой теме. Модель способна отвечать на уточняющие вопросы, раскрывать определения.
По сути, в ее распоряжении накопленные знания человечества в конкретной предметной области. Этого более чем достаточно для генерации полноценных статей с нужным углом освещения темы. Причем современные модели уже позволяют получать такие тексты абсолютно бесплатно в рамках базовых лимитов.
Таким образом, применение языковых ИИ-моделей открывает новый источник уникального качественного контента для сайтов. Это позволит хотя бы частично решить постоянную проблему нехватки такого контента в SEO и контент-маркетинге. Генерация автоматических текстов с помощью ИИ – многообещающее направление развития этих сфер.
Проблемы при работе с большими языковыми моделями
Хотя качество текстов, генерируемых ИИ-моделями, уже довольно высоко, встречаются и некоторые типичные огрехи.
Во-первых, возможны “галлюцинации” – когда модель пишет о несуществующих вещах, про которые у нее просто не было данных в обучающей выборке. Такие вещи нужно выверять вручную и исправлять самостоятельно.
Во-вторых, при работе с русским языком могут встречаться вкрапления слов, части слов или целых фраз на английском – так называемые “артефакты” из-за того, что бóльшая часть данных для обучения была на английском.
Еще одна распространенная ранее проблема – сложность генерации больших по объему текстов, модель как бы “уставала” на полпути. Однако в последних версиях (GPT-3, Claude 2) эта проблема практически решена.
Однако чтобы максимально эффективно использовать возможности ИИ, лучше сначала попросить его сгенерировать подробный план будущей статьи, отредактировать его, а затем уже просить написать полные разделы. Так можно получать развернутые SEO-статьи практически без усилий. И гораздо быстрее, дешевле и качественнее, чем при работе с любым копирайтером.
Создание списков поисковых запросов и их кластеризация при помощи нейронных сетей
Языковые ИИ-модели предоставляют широкие возможности автоматизации различных SEO-процессов.
Они способны самостоятельно генерировать целевые поисковые запросы по заданной тематике и группировать их по смысловой близости в тематические кластеры. Это избавляет от необходимости ручного анализа больших массивов ключевых слов, кластеризацию их с помощью различных сервисов и экономит массу времени SEO-специалиста.

ИИ также помогает с разработкой контент-стратегии, предлагая список популярных информационных запросов аудитории, в том числе по узкоспециализированным темам вроде ссылочного продвижения. А затем даже способен автоматически генерировать тексты под каждую релевантную тему.

Такой симбиоз современных языковых моделей и классического SEO открывает огромные перспективы для повышения качества и масштабирования работы в этой сфере. А такая автоматизация многих рутинных процессов позволяет оптимизатору сконцентрироваться на более сложных задачах.
Использование Retrieval Augmented Generation (RAG) для работы LLM со своими данными
Наибольшую эффективность применения языковых ИИ-моделей в SEO дает их дообучение (fine-tuning) на специализированных данных, релевантных вашей бизнес-тематике и целевой аудитории.
Один из подходов – RAG (Retrieval Augmented Generation). Суть в том, чтобы в промпте, формулирующем задание для ИИ, сразу указать дополнительные данные, на которых вы хотите, чтобы модель основывалась при генерации контента.
Например, можно подготовить подборку статей, исследований, кейсов именно по вашей нише и в промпте указать: “Используй следующие материалы как основу для написания текста: …”.
Таким образом модель будет генерировать SEO-контент, максимально релевантный вашему бизнесу и тем самым эффективный для продвижения вашего сайта в поисковиках.
Технологии языкового ИИ позволяют с легкостью масштабировать такой подход на тысячи запросов и получать уникальный целевой контент практически на автомате.
Создание текста страницы по ключевым словам при помощи нейросети на основе анализа страницы-донора
RAG-подход позволяет с легкостью интегрировать в процесс генерации SEO-контента данные с вашего сайта или сайтов конкурентов. Можно, к примеру, загрузить в модель PDF-версию главной страницы лидирующего конкурента и попросить выделить оттуда ключевые слова.
А дальше сформулировать задание типа: “Напиши новую уникальную статью объемом 800 слов на тему продвижения сайтов, используя следующий список ключевиков: …”. Таким образом мы получим SEO-контент, основанный на актуальной семантике, но при этом уникальный, без рерайта.
Можно применить аналогичный подход и к страницам своего ресурса – ИИ проанализирует текущую семантику, а затем сгенерирует новые уникальные материалы с учетом уже разработанной тематики.
Такой инструментарий открывает практически безграничные возможности для масштабирования производства эффективного SEO-контента. Можно формировать сотни уникальных статей за считанные минуты, причем максимально целевых и оптимизированных под ваши запросы.
Создание вариантов заголовков страниц с высоким CTR при помощи ИИ
Возможности языковых ИИ-моделей поистине безграничны. В их число входит даже генерация заголовков и мета-описаний для статей с максимальной оптимизацией под кликабельность (CTR).
Достаточно в промпте сформулировать соответствующее задание, указав целевые параметры, например: “Предложи 20 вариантов заголовков для статьи на тему XX, которые имели бы высокий CTR”.

Модель проанализирует тематику, уловит суть информации, а затем сгенерирует много вариантов заголовков с акцентом на пользу для читателя, преимущества, реальные примеры – такие формулировки статистически показывают наибольший процент кликов.
Более того, некоторые модели даже пояснят, почему были выбраны именно такие формулировки, на что сделан акцент. Это позволяет с легкостью генерировать варианты уникальных SEO-оптимизированных заголовков за считанные минуты.
Генерация мета-тегов и микроразметки при помощи нейросетей
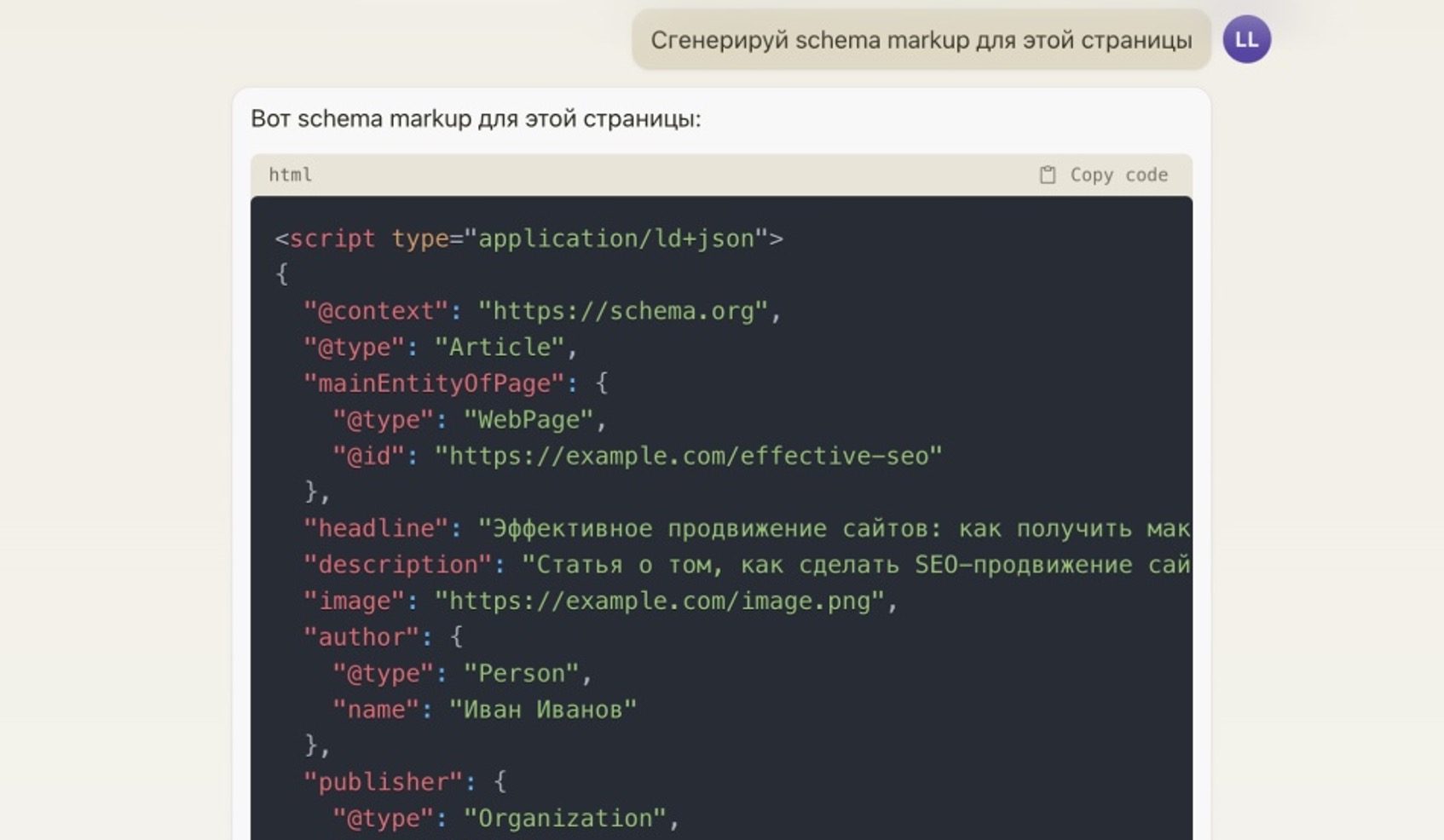
Языковые модели способны также формировать мета-теги и микроразметку для SEO-статей. Достаточно в промпте указать соответствующее задание, и ИИ сгенерирует не только title для документа, но и description, основные и дополнительные мета-теги, JSON микроразметку со всеми необходимыми семантическими данными.

Более того, если в процессе выяснится, что требуются какие-то правки, можно просить модель переписать мета-данные с учетом новых условий. Например, добавить информацию об авторе статьи или об адресе сайте.
Как сделать рерайт статьи при помощи нейросети
Еще одним примером широчайших возможностей современных языковых моделей ИИ является написание статей на основе других текстов с нужной глубиной раскрытия темы.
Можно в промпте указать ссылку или загрузить файл со статьей на определенную тему, а затем попросить ИИ переписать ее “своими словами”, добавив дополнительные подробности. Например: “Напиши подробную статью на основе этого текста и в конце добавь информацию о компании XXX”.
ИИ проанализирует исходный материал, извлечет ключевую суть, а затем сгенерирует новый уникальный текст с сохранением основной информации, дополнительными деталями и заданными вставками. По запросу статью можно разбить на подзаголовки или отредактировать в нужном ключе. Такой функционал фактически заменяет копирайтера, выполняя все необходимые действия в автоматическом режиме. Это позволяет программно перерабатывать и адаптировать уже существующий контент под нужды SEO и контент-маркетинга.
Также возможна автоматическая разметка кода статьи при помощи HTML-тегов.
Российские аналоги ChatGPT
Среди языковых моделей искусственного интеллекта лидирующие позиции занимают западные разработки вроде GPT-3 и Claude. Российские аналоги (YandexGPT от Яндекса, GigaChat от Сбера) пока уступают им в качестве работы с русскоязычным контентом.
Это связано с тем, что у отечественных ИИ нет доступа к сопоставимым объемам обучающих данных на русском языке. В лучшем случае они могут достичь уровня прошлых версий западных моделей.
Чтобы существенно превзойти текущих лидеров, российским разработчикам потребовались бы не только большие вычислительные мощности, но и гораздо больший объем русскоязычных текстов. Таким образом, проще и дешевле использовать уже готовые решения от OpenAI, Anthropic и других западных лабораторий. Они уже сейчас качественно справляются с автоматизированной генерацией русскоязычного контента.
Генерация изображений для сайта при помощи искусственного интеллекта
Помимо текстов, современные ИИ модели умеют работать и с графическим контентом. Они могут не только анализировать изображения, но и самостоятельно генерировать нужные картинки по текстовому описанию.
Одна из таких моделей – Stable Diffusion – предоставляет ряд полезных для маркетолога инструментов. Можно загрузить любое изображение и попросить ИИ изменить или дополнить его нужными деталями. Скажем, добавить в пейзаж еще одного персонажа или заменить фон.
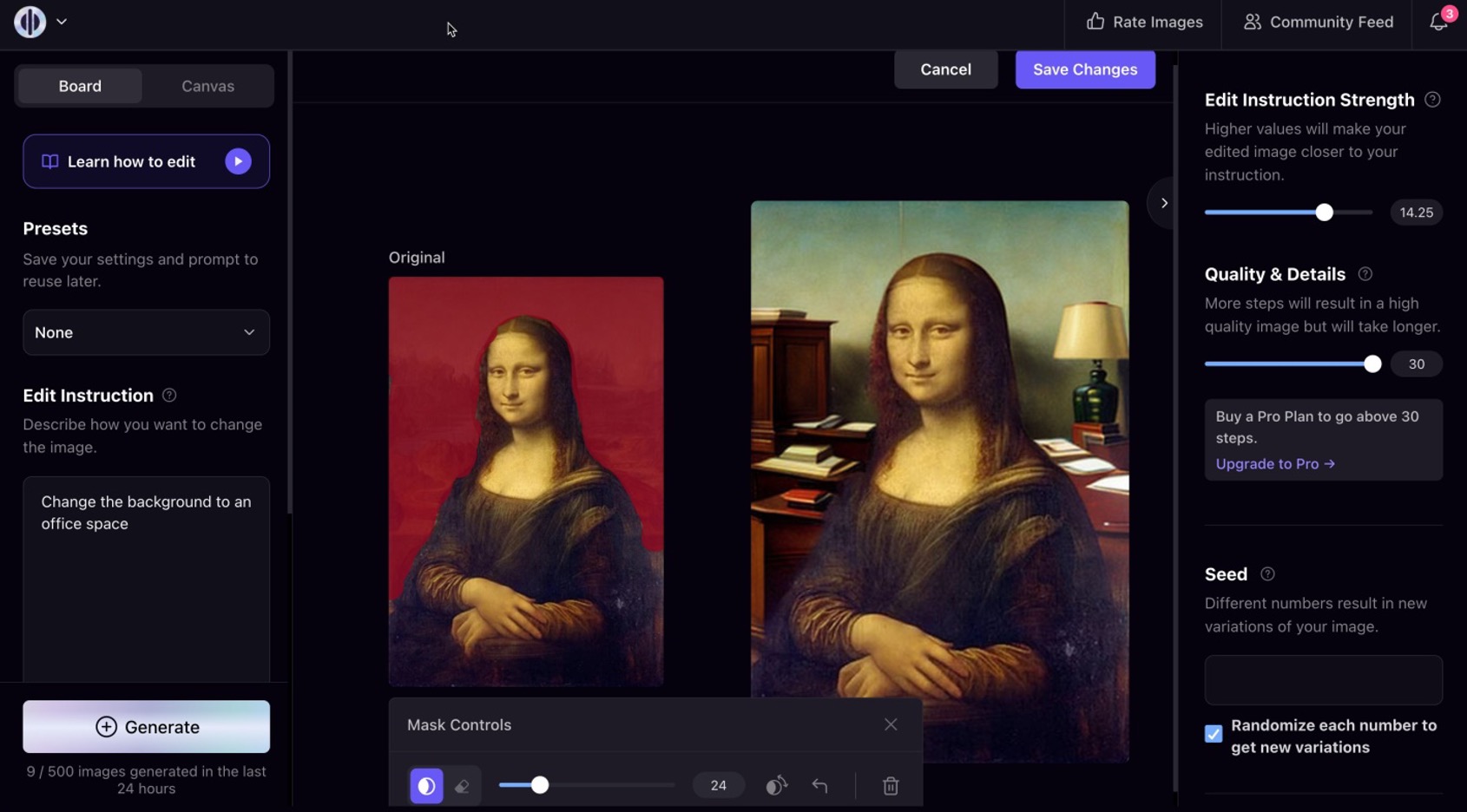
Есть режим расширения картинки за пределы кадра, возможность редактирования отдельных объектов, смены стиля и многое другое.
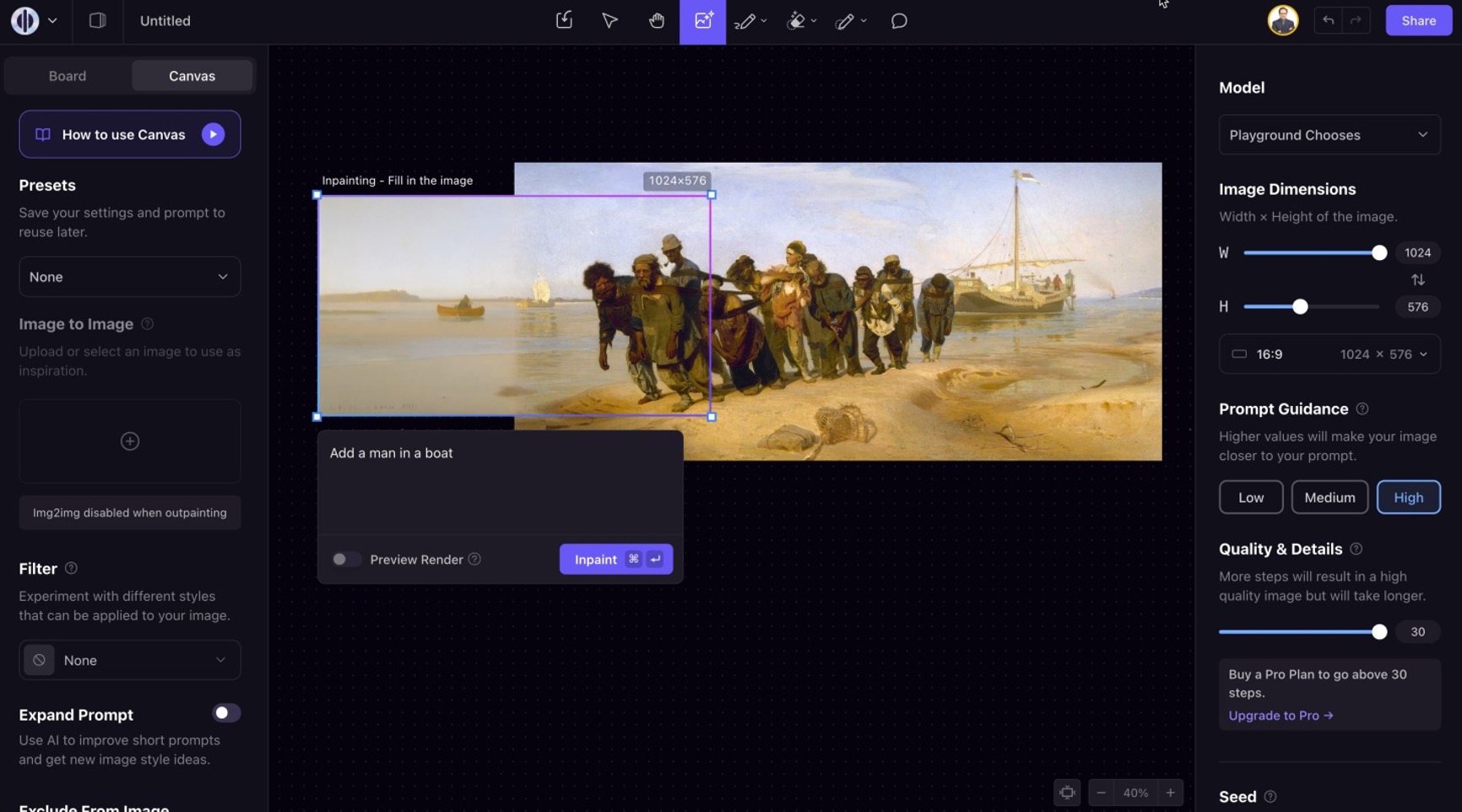
А можно просто текстом описать нужную сцену или объект – и получить реалистичное фото заданного вида, с чем великолепно справляется последняя шестая версия MidJourney.
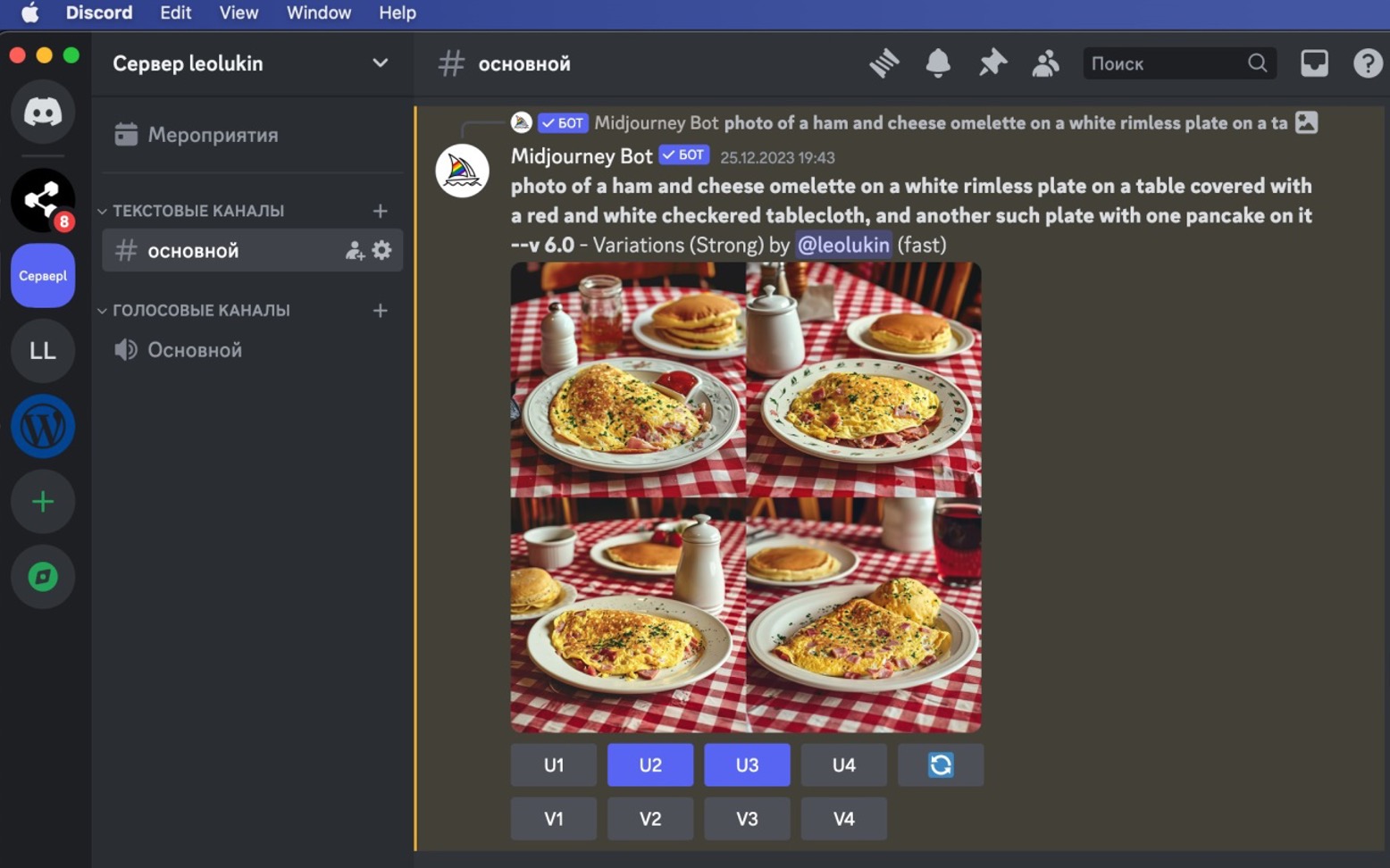
Все это открывает широкие горизонты для быстрого создания уникальных изображений для SEO-статей, соцсетей, рекламы. Это позволяет, например, проиллюстрировать статьи или сгенерировать картинки товаров для конкретного интернет-магазина. Технологии ИИ кардинально упрощают и ускоряют работу с визуальным контентом.
